Spark Authorizer 

Spark Authorizer provides you with SQL Standard Based Authorization for Apache Spark™ as same as SQL Standard Based Hive Authorization. While you are using Spark SQL or Dataset/DataFrame API to load data from tables embedded with Apache Hive™ metastore, this library provides row/column level fine-grained access controls by Apache Ranger™ or Hive SQL Standard Based Authorization.
Security is one of fundamental features for enterprise adoption. Apache Ranger™ offers many security plugins for many Hadoop ecosystem components, such as HDFS, Hive, HBase, Solr and Sqoop2. However, Apache Spark™ is not counted in yet. When a secured HDFS cluster is used as a data warehouse accessed by various users and groups via different applications wrote by Spark and Hive, it is very difficult to guarantee data management in a consistent way. Apache Spark users visit data warehouse only with Storage based access controls offered by HDFS. This library shares Ranger Hive plugin with Hive to help Spark talking to Ranger Admin.
Please refer to ACL Management for Spark SQL to see what spark-authorizer supports.
Quick Start
Step 1. Install Spark Authorizer
Include this package in your Spark Applications using:
spark-shell, pyspark, or spark-submit
> $SPARK_HOME/bin/spark-shell --packages yaooqinn:spark-authorizer:2.1.1
sbt
If you use the sbt-spark-package plugin, in your sbt build file, add:
spDependencies += "yaooqinn/spark-authorizer:2.1.1"
Otherwise,
resolvers += "Spark Packages Repo" at "http://dl.bintray.com/spark-packages/maven"
libraryDependencies += "yaooqinn" % "spark-authorizer" % "2.1.1"
Maven
In your pom.xml, add:
<dependencies>
<!-- list of dependencies -->
<dependency>
<groupId>yaooqinn</groupId>
<artifactId>spark-authorizer</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<repositories>
<!-- list of other repositories -->
<repository>
<id>SparkPackagesRepo</id>
<url>http://dl.bintray.com/spark-packages/maven</url>
</repository>
</repositories>
Manully
If you Building Spark Authorizer manully, you can deploy via:
cp target/spark-authorizer-<version>.jar $SPARK_HOME/jars
Step 2. Install & Configure Ranger Hive Plugin
Please refer to Install Ranger Hive Plugin For Apache Spark to learn how to deploy the plugin jars to Apache Spark and set Ranger/Hive configurations.
Step 3. Enable Spark Authorizer
In $SPARK_HOME/conf/spark-defaults.conf, add:
spark.sql.extensions=org.apache.ranger.authorization.spark.authorizer.RangerSparkSQLExtension
NOTE spark.sql.extensions is only supported by Spark 2.2.x and later, for Spark 2.1.x please use Version: 1.1.3.spark2.1 and check the previous doc.
Interactive Spark Shell
The easiest way to start using Spark is through the Scala shell:
bin/spark-shell --master yarn --proxy-user hzyaoqin
Suffer for the Authorization Pain
We create a ranger policy as below:
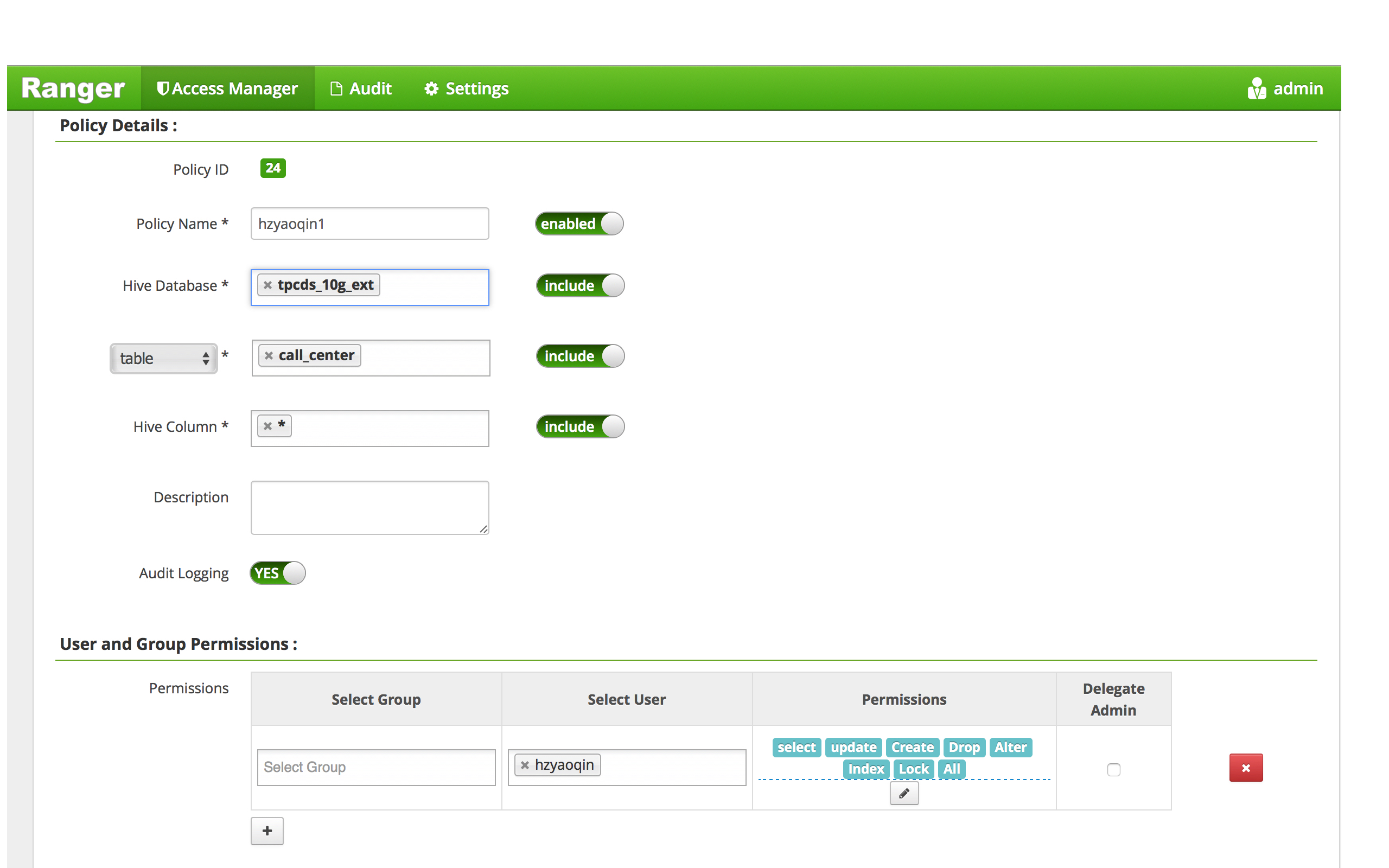
Check Privilege with some simple cases.
Show databases
scala> spark.sql("show databases").show
+--------------+
| databaseName|
+--------------+
| default|
| spark_test_db|
| tpcds_10g_ext|
+--------------+
Switch database
scala> spark.sql("use spark_test_db").show
17/12/08 17:06:17 ERROR optimizer.Authorizer:
+===============================+
|Spark SQL Authorization Failure|
|-------------------------------|
|Permission denied: user [hzyaoqin] does not have [USE] privilege on [spark_test_db]
|-------------------------------|
|Spark SQL Authorization Failure|
+===============================+
Oops…
scala> spark.sql("use tpcds_10g_ext").show
++
||
++
++
LOL…
Select
scala> spark.sql("select cp_type from catalog_page limit 1").show
17/12/08 17:09:58 ERROR optimizer.Authorizer:
+===============================+
|Spark SQL Authorization Failure|
|-------------------------------|
|Permission denied: user [hzyaoqin] does not have [SELECT] privilege on [tpcds_10g_ext/catalog_page/cp_type]
|-------------------------------|
|Spark SQL Authorization Failure|
+===============================+
Oops…
scala> spark.sql("select * from call_center limit 1").show
+-----------------+-----------------+-----------------+---------------+-----------------+---------------+--------+--------+------------+--------+--------+-----------+---------+--------------------+--------------------+-----------------+-----------+----------------+----------+---------------+----------------+--------------+--------------+---------------+-------+-----------------+--------+------+-------------+-------------+-----------------+
|cc_call_center_sk|cc_call_center_id|cc_rec_start_date|cc_rec_end_date|cc_closed_date_sk|cc_open_date_sk| cc_name|cc_class|cc_employees|cc_sq_ft|cc_hours| cc_manager|cc_mkt_id| cc_mkt_class| cc_mkt_desc|cc_market_manager|cc_division|cc_division_name|cc_company|cc_company_name|cc_street_number|cc_street_name|cc_street_type|cc_suite_number|cc_city| cc_county|cc_state|cc_zip| cc_country|cc_gmt_offset|cc_tax_percentage|
+-----------------+-----------------+-----------------+---------------+-----------------+---------------+--------+--------+------------+--------+--------+-----------+---------+--------------------+--------------------+-----------------+-----------+----------------+----------+---------------+----------------+--------------+--------------+---------------+-------+-----------------+--------+------+-------------+-------------+-----------------+
| 1| AAAAAAAABAAAAAAA| 1998-01-01| null| null| 2450952|NY Metro| large| 2| 1138| 8AM-4PM|Bob Belcher| 6|More than other a...|Shared others cou...| Julius Tran| 3| pri| 6| cally| 730| Ash Hill| Boulevard| Suite 0| Midway|Williamson County| TN| 31904|United States| -5.00| 0.11|
+-----------------+-----------------+-----------------+---------------+-----------------+---------------+--------+--------+------------+--------+--------+-----------+---------+--------------------+--------------------+-----------------+-----------+----------------+----------+---------------+----------------+--------------+--------------+---------------+-------+-----------------+--------+------+-------------+-------------+-----------------+
LOL…
Dataset/DataFrame
scala> spark.read.table("catalog_page").limit(1).collect
17/12/11 14:46:33 ERROR optimizer.Authorizer:
+===============================+
|Spark SQL Authorization Failure|
|-------------------------------|
|Permission denied: user [hzyaoqin] does not have [SELECT] privilege on [tpcds_10g_ext/catalog_page/cp_catalog_page_sk,cp_catalog_page_id,cp_promo_id,cp_start_date_sk,cp_end_date_sk,cp_department,cp_catalog_number,cp_catalog_page_number,cp_description,cp_type]
|-------------------------------|
|Spark SQL Authorization Failure|
+===============================+
Oops…
scala> spark.read.table("call_center").limit(1).collect
res3: Array[org.apache.spark.sql.Row] = Array([1,AAAAAAAABAAAAAAA,1998-01-01,null,null,2450952,NY Metro,large,2,1138,8AM-4PM,Bob Belcher,6,More than other authori,Shared others could not count fully dollars. New members ca,Julius Tran,3,pri,6,cally,730,Ash Hill,Boulevard,Suite 0,Midway,Williamson County,TN,31904,United States,-5.00,0.11])
LOL…