这是 Spark SQL Metrics 深度解析系列的第六部分:
- 第一部分:指标类型、完整参考和含义
- 第二部分:内部实现机制,以及 AQE 如何利用指标做出运行时决策
- 第三部分:扩展 API、UI 渲染和 REST API
- 第四部分:Gluten 如何扩展指标系统
- 第五部分:Gluten 指标内部机制 — 节点映射、管道聚合、MetricsUpdaterTree
- 第六部分(本文):实战 — 以 TPC-DS q99 为例,逐算子解读 Gluten/Velox 指标
在前五部分中,我们搭建了完整的知识体系:指标类型、内部流转机制、扩展 API、Gluten 的架构设计、以及原生端的聚合机制。现在,是时候把这些知识付诸实践了。我们将打开一个真实查询的 Spark UI,逐算子走读每个指标,展示如何从指标中读懂查询执行的全貌。
查询:TPC-DS q99
TPC-DS q99 是一个 5 表关联查询,分析目录销售的发货延迟情况,按仓库、发货方式和呼叫中心分组。它将发货延迟分为不同区间(31–60 天、61–90 天、91–120 天、120 天以上),然后按延迟情况排序。
我们在一个集群上以 SF10000(10 TB 原始数据量)运行了这个查询,使用 Gluten/Velox 作为原生执行后端,底层存储为云对象存储上的 Delta Lake 表。
查询计划遵循经典的星型模式:
catalog_sales(事实表,33 亿行)
→ BroadcastHashJoin 关联 date_dim
→ BroadcastHashJoin 关联 ship_mode
→ BroadcastHashJoin 关联 call_center
→ BroadcastHashJoin 关联 warehouse
→ 部分 HashAggregate
→ Shuffle(哈希分区)
→ AQE 合并
→ 最终 HashAggregate
→ TakeOrderedAndProject(取前 100 条)
本文中所有数字均为真实数据。让我们逐算子走读指标,看看它们告诉了我们什么。
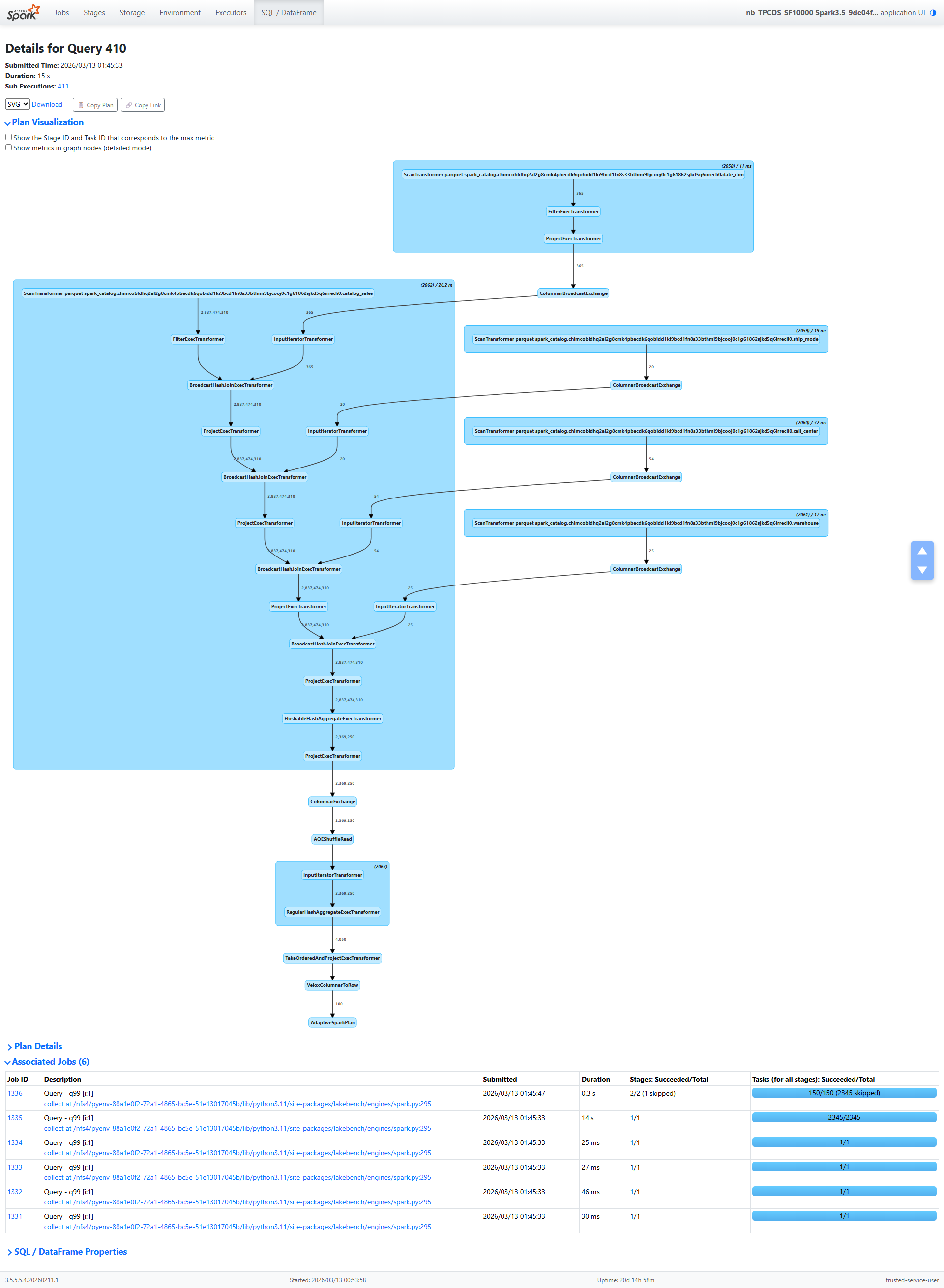
第一节:事实表扫描 — 33 亿行
计划中的第一个算子是 ScanTransformer catalog_sales。一切从这里开始,这里的指标讲述了一个精彩的故事。
数据规模
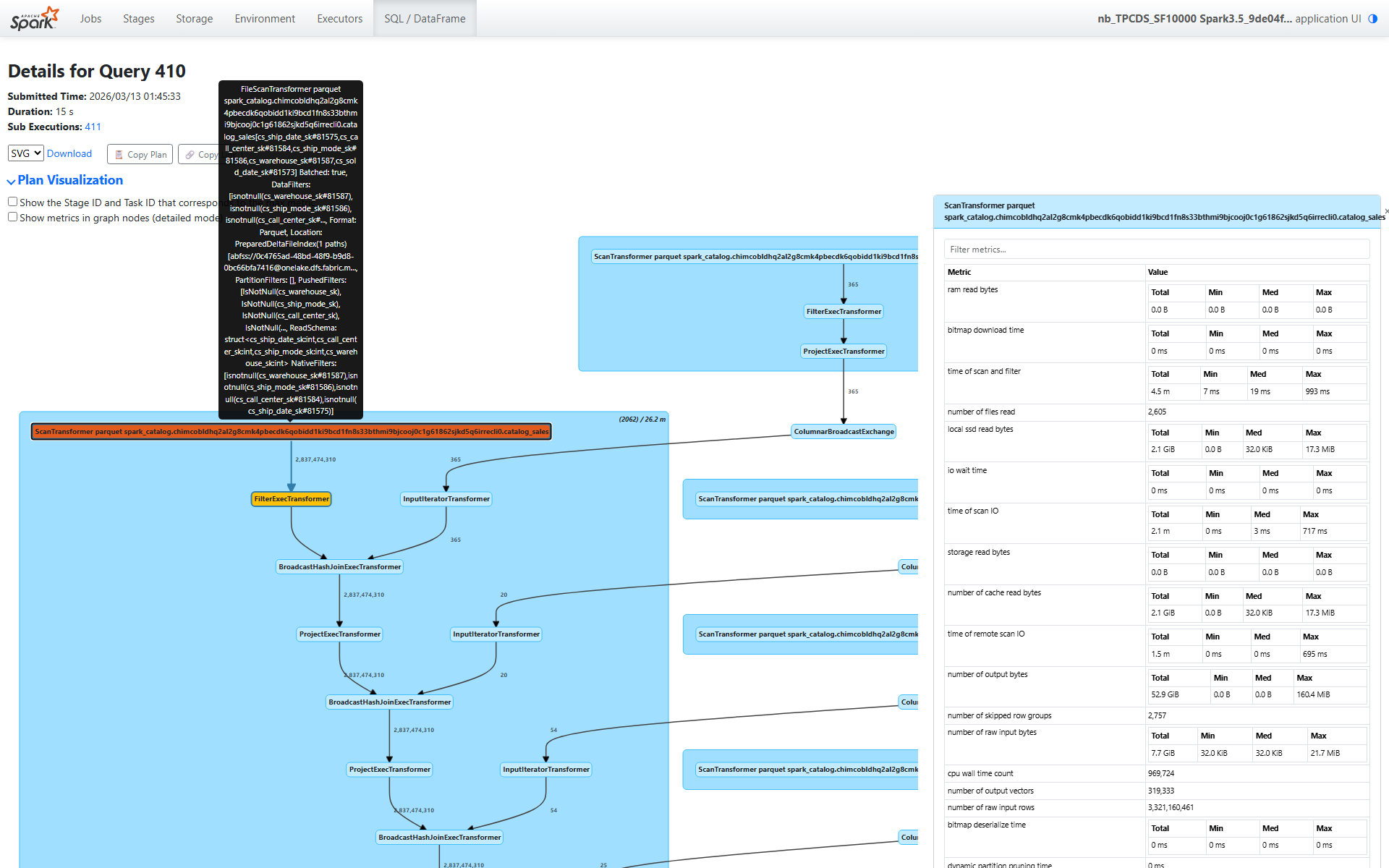
number of raw input rows(原始输入行数):3,321,160,461 — 33 亿行number of output rows(输出行数):2,837,474,310 — 谓词下推淘汰部分行组后剩余 28 亿行size of files read(读取文件大小):910.9 GiB,涉及 2,605 个文件、1,837 个分区
这是一次大规模扫描。但看看它的服务效率有多高。
I/O 层级 — 缓存的故事
这里才是真正有趣的地方:
storage read bytes(存储读取字节数):0.0 B — 零字节来自远程存储!local ssd read bytes(本地 SSD 读取字节数):2.1 GiB — 所有数据均来自本地 SSD 缓存ram read bytes(内存读取字节数):0.0 B — 没有内存缓存命中number of cache read bytes(缓存读取字节数):2.1 GiB — 与本地 SSD 数字完全一致
想想这意味着什么:表在磁盘上占据 910.9 GiB,但我们只需要读取 2.1 GiB 的实际数据。这是 99.8% 的缩减。两个因素共同作用:
- 列式存储效率 — 我们只读取了查询引用的列(仅占表总列数的一小部分)
- 行组级谓词下推 — Parquet/Delta 的统计信息让 Velox 可以跳过 min/max 范围不匹配的整个行组
而且这 2.1 GiB 全部来自本地 SSD 缓存——没有一个字节需要通过网络访问远程存储。
行组裁剪
number of skipped row groups(跳过的行组数):2,757
Velox 检查了行组统计信息,完全跳过了 2,757 个行组。这些行组包含的数据不在谓词范围内(date_dim 的过滤条件限制了 d_month_seq 的范围,这转化为 cs_sold_date_sk 上的范围过滤)。这就是我们从 910.9 GiB 的文件中只需读取 2.1 GiB 的主要原因。
动态过滤器
number of dynamic filters accepted(接受的动态过滤器数):9,380
这是一个强大的优化。在执行过程中,每个 broadcast hash join 的 Build 端会生成一个过滤器(一组关联键值或 Bloom 过滤器),这些过滤器在运行时被下推到 Scan 算子。通过应用 9,380 个动态过滤器,Scan 算子在数据到达 join 算子之前就淘汰了不匹配的行。
如果你读过第四部分,你会知道 Gluten 在扫描层面记录了动态过滤器的接受情况。这个指标告诉我们:运行时过滤器确实生成并应用了,而且确实有帮助。
耗时分析
time of scan and filter(扫描和过滤时间):4.5 分钟(所有任务总计)time of scan IO(扫描 I/O 时间):2.1 分钟 — 约一半的扫描时间用于 I/Ocpu wall time count(CPU Wall Clock Time 计数):969,724 个批次被处理
扫描处理了近百万个批次。I/O 时间(2.1 分钟)与总扫描时间(4.5 分钟)的对比告诉我们,大约一半时间用于 I/O,一半用于 CPU 工作(解压缩、谓词评估、列提取)。
任务分布
从 min/median/max 分布来看:
- 每个任务读取的字节数:中位数 32 KiB,最大值 17.3 MiB — 数据分布存在适度倾斜
- 每个任务的峰值内存:中位数 32 KiB,最大值 29.9 MiB
大多数任务处理的数据量很小(表被分散到 1,837 个分区),但某些分区明显更大。这在真实数据中很常见 — 完全均匀的分区分布是罕见的。
第二节:四个 Broadcast Hash Join — 28 亿行探测
扫描之后,计划链式执行了四个 broadcast hash join。每个 join 将事实表与一个维度表关联:date_dim、ship_mode、call_center 和 warehouse。我们先详细走读 date_dim join(节点 [18]),然后总结四个 join 的共同模式。
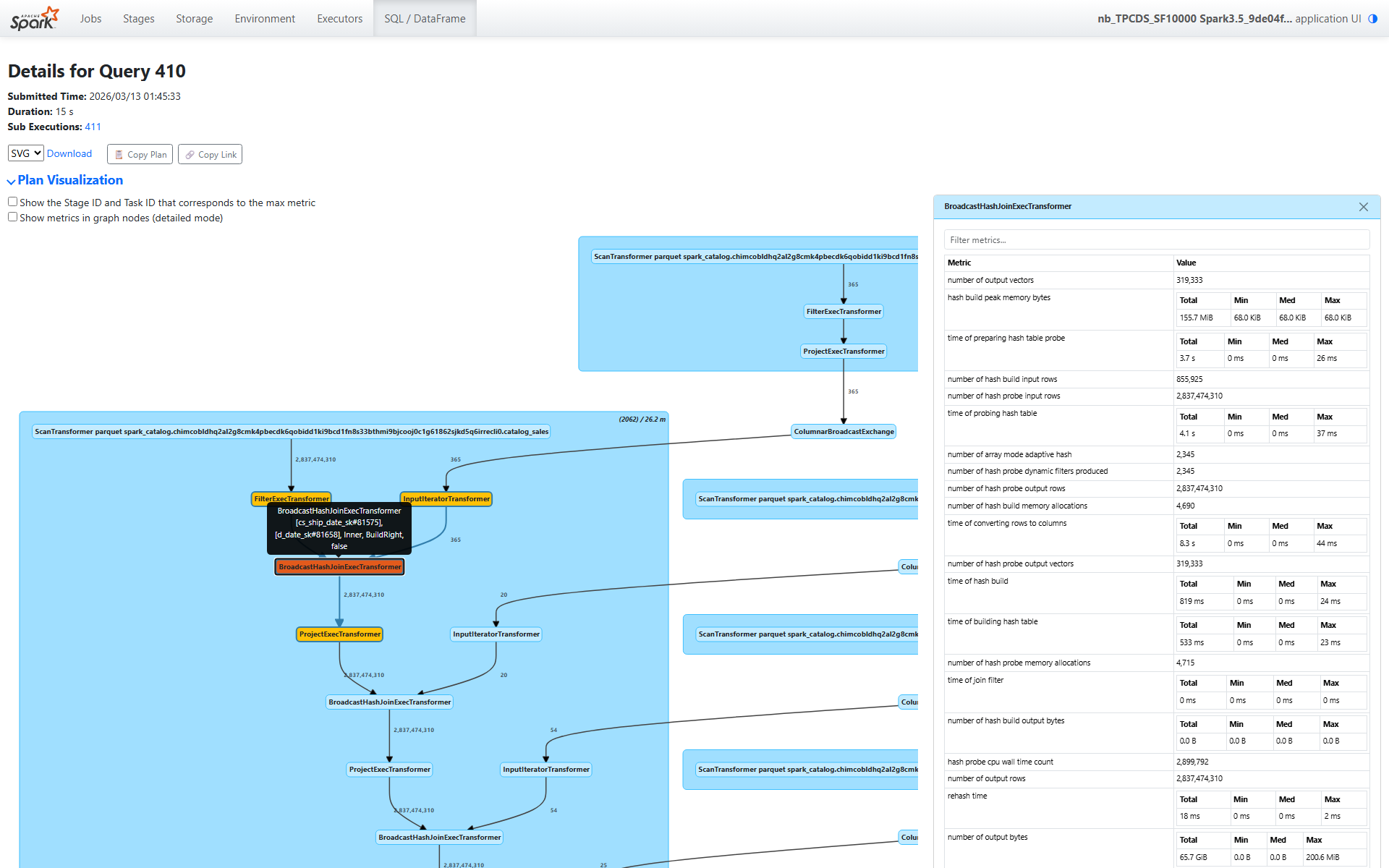
Build 端(date_dim)
number of hash build input rows(哈希构建输入行数):855,925(广播后各分区的 date_dim 行数)time of hash build(哈希构建时间):819 ms — 快速,维度表很小time of building hash table(构建 Hash Table 时间):533 ms — 实际的 Hash Table 构建hash build peak memory bytes(哈希构建峰值内存):155.7 MiB 总计(每个任务 68 KiB — 非常小)
Build 端微不足道。date_dim 只有几十万行,广播后每个任务获得一份副本。构建 Hash Table 的时间远低于一秒。
Probe 端
现在看 Probe 端 — 这才是真正的工作所在:
number of hash probe input rows(哈希探测输入行数):2,837,474,310 — 来自扫描的全部 28 亿行time of hash probe(哈希探测时间):31.4 秒总计time of probing hash table(探测 Hash Table 时间):4.1 秒 — 实际的哈希查找time of preparing hash table probe(准备 Hash Table 探测时间):3.7 秒 — 反序列化广播数据time of converting rows to columns(行转列时间):8.3 秒 — 列式格式转换
注意这个分解:在 31.4 秒的总探测时间中,只有 4.1 秒用于实际的哈希查找。其余是开销 — 反序列化、格式转换和管道协调。这对于 broadcast join 来说是典型的:哈希查找本身很快(Hash Table 可以放入 L2/L3 缓存),但将 28 亿行通过管道传输需要时间。
生成的动态过滤器
number of hash probe dynamic filters produced(哈希探测产生的动态过滤器数):2,345
处理这个 join 的每个任务都从 Build 端的键值生成了一个动态过滤器。这 2,345 个过滤器被推回到 Scan 算子(对我们之前看到的 9,380 个动态过滤器有贡献 — 多个 join 共同贡献过滤器)。
零 Spill
bytes written for spilling of hash build(哈希构建 Spill 字节数):0.0 Bbytes written for spilling of hash probe(哈希探测 Spill 字节数):0.0 B
完美。维度表足够小,可以完全放入内存。所有 join 过程中没有任何数据 Spill 到磁盘。
输出
number of hash probe output rows(哈希探测输出行数):2,837,474,310 — 全部 28 亿行通过- 输出数据量:65.7 GiB(输出增大是因为添加了维度表的列)
所有行都通过了,因为谓词下推和动态过滤器已经在扫描阶段淘汰了不匹配的行。join 本身只是在每行上追加维度属性。
四个 Join 的对比
以下是四个 broadcast hash join 的汇总对比:
| Join | 构建表 | 构建行数 | 探测时间 | 后 Project 时间 |
|---|---|---|---|---|
| date_dim | date_dim | 855,925 | 31.4s | 8.1s |
| ship_mode | ship_mode | 46,900 | 1.6 min | 8.0s |
| call_center | call_center | 126,630 | 2.4 min | 8.1s |
| warehouse | warehouse | 58,625 | 2.8 min | 8.2s |
注意探测时间随着每个后续 join 逐渐增加。这不是因为后面的 join 更慢 — 而是因为 wallNanos(探测时间指标的底层计时器)包含子算子的等待时间。正如我们在第四部分中解释的,每个算子的 Wall Clock Time 包括等待子算子提供数据的时间。warehouse join(最外层)包含了下面三个 join 和扫描的全部时间。
后 Project 时间非常一致(约 8 秒),这合情合理 — 每个 join 追加几列,Project 工作量与输出大小成正比,而每个阶段的输出大小大致相同(28 亿行)。
第三节:聚合 — 28 亿 → 230 万行
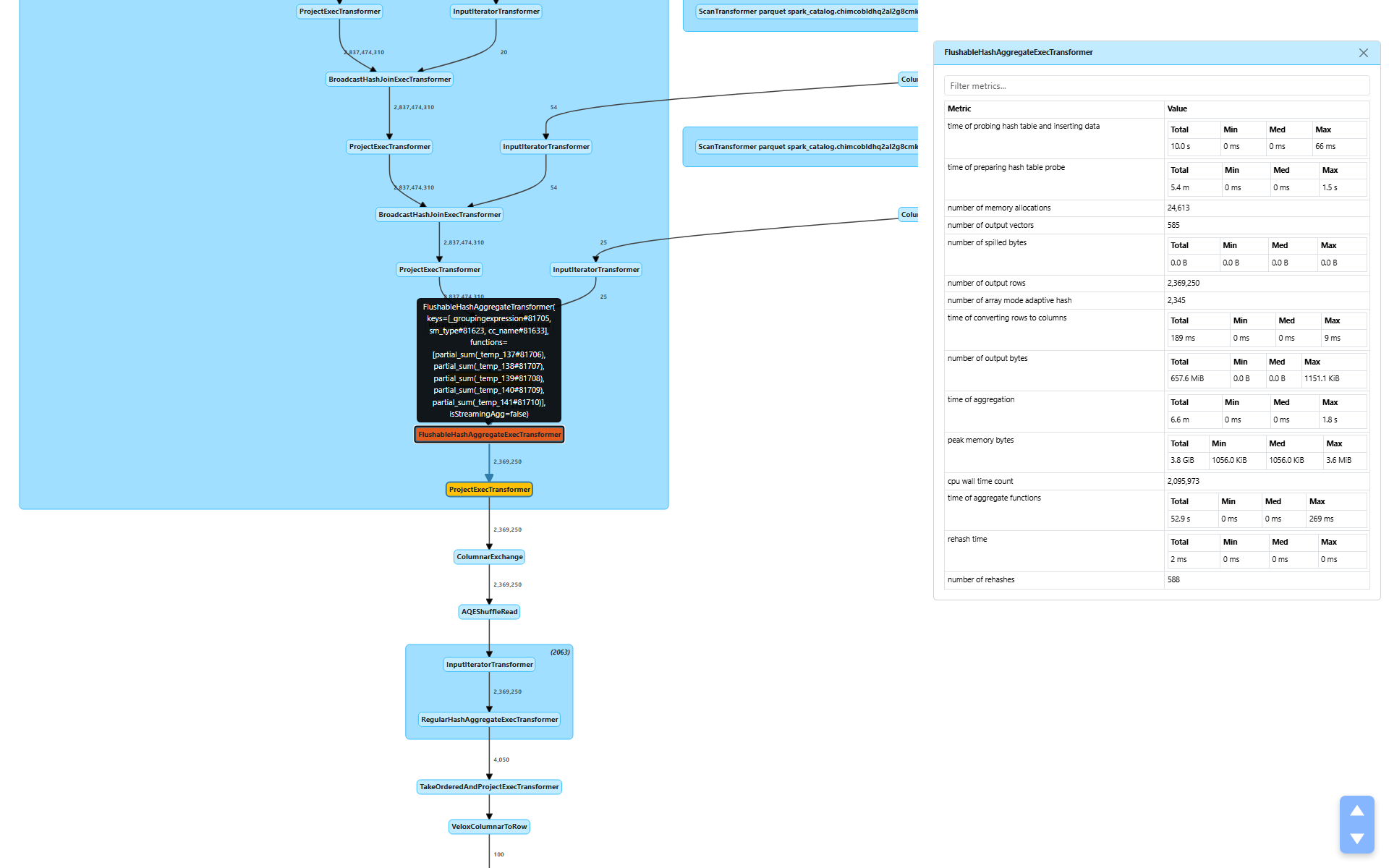
四个 join 之后,计划应用了 FlushableHashAggregateExecTransformer(节点 [10])进行部分聚合。这是数据量急剧下降的地方。
number of output rows(输出行数):2,369,250 — 从 28 亿输入行实现了 1,200 倍缩减time of aggregation(聚合时间):6.6 分钟time of aggregate functions(聚合函数时间):52.9 秒 — 实际的 SUM() 计算time of preparing hash table probe(准备 Hash Table 探测时间):5.4 分钟 — 主要是子算子等待时间(上面的 join)peak memory bytes(峰值内存):3.8 GiB 总计(每个任务最大 3.6 MiB)number of spilled bytes(Spill 字节数):0.0 B — 无需 Spillnumber of output vectors(输出向量数):585 — 28 亿输入行只产生了 585 个输出批次
1,200 倍的缩减告诉我们,group-by 键(仓库、发货方式、呼叫中心、日期区间)虽然有一定的基数,但产生的分组数远少于输入行数。实际的聚合计算(SUM)只花了 52.9 秒 — 6.6 分钟聚合时间中的大部分是从扫描和 join 层层上传的子算子等待时间。
WholeStageCodegenTransformer
从扫描到四个 join 再到部分聚合的整个原生管道,在一个 WholeStageCodegenTransformer 中运行:
duration(持续时间):26.2 分钟总计(每个任务最大 6.6 秒)
这是原生执行管道的端到端时间。它涵盖了我们目前讨论的所有内容:扫描 33 亿行、28 亿行的四个 broadcast hash join、以及聚合至 230 万行 — 全部在 Velox 的向量化原生引擎中执行。
第四节:Shuffle — 基于哈希,紧凑高效
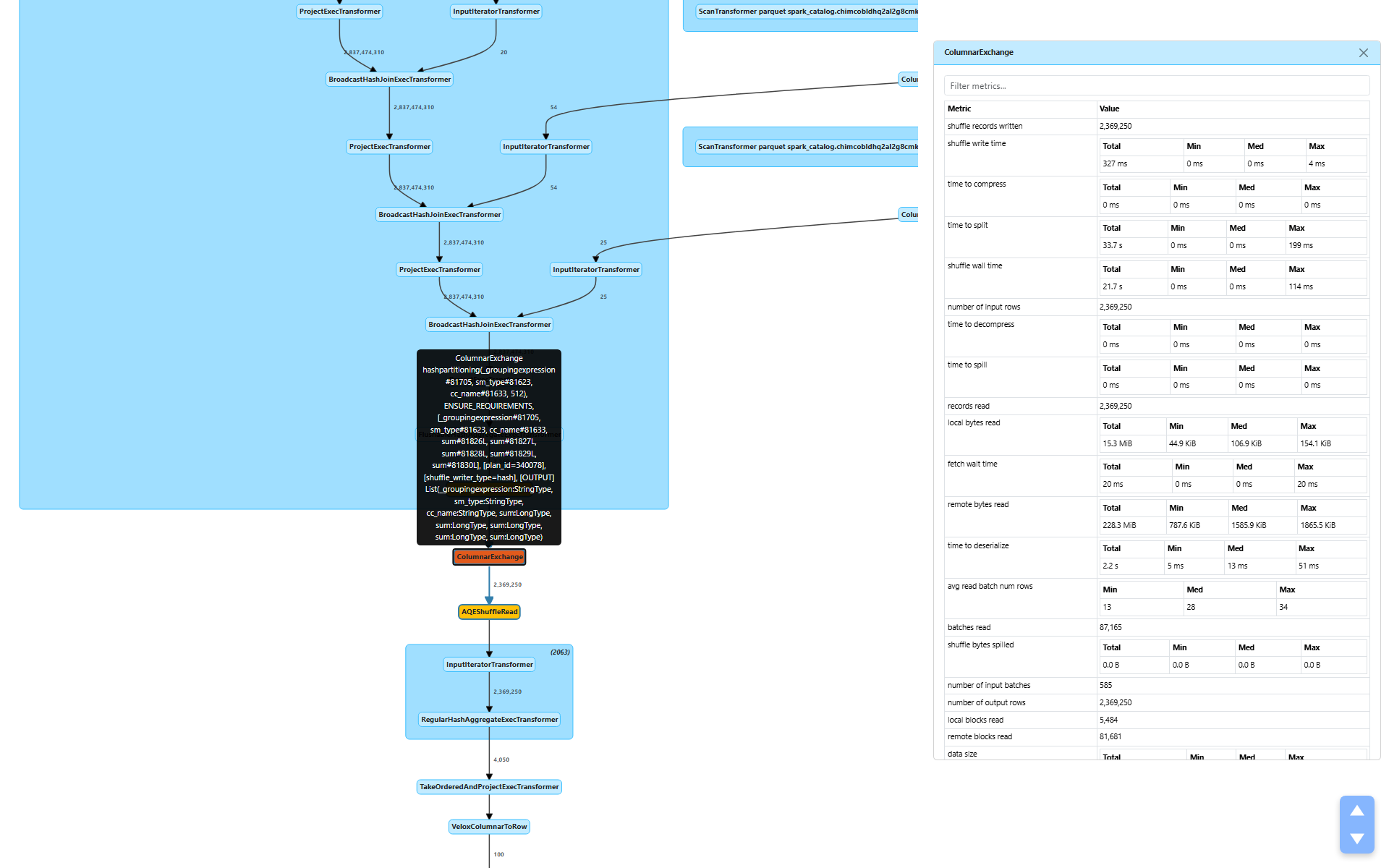
部分聚合之后,计划通过 ColumnarExchange(节点 [7])执行 shuffle,按 group-by 键重新分配数据以进行最终聚合。
写入端
shuffle bytes written(shuffle 写入字节数):243.6 MiB — 非常小shuffle write time(shuffle 写入时间):327 mstime to split(分区时间):33.7 秒 — 哈希分区为 512 个分区shuffle wall time(shuffle Wall Clock Time):21.7 秒shuffle bytes spilled(shuffle Spill 字节数):0.0 B — 完全放入内存peak bytes allocated(峰值分配字节数):255.1 GiB 总计(每个任务最大 446.5 MiB)
聚合将 28 亿行缩减到 230 万行,这 230 万行序列化后仅为 243.6 MiB。与我们起始的 910.9 GiB 事实表相比 — 聚合使得 shuffle 几乎微不足道。
分区时间(33.7 秒)是将输出哈希分区到 512 个桶的时间。实际写入时间(327 ms)很快,因为数据量极小。
读取端
remote bytes read(远程读取字节数):228.3 MiBlocal bytes read(本地读取字节数):15.3 MiBremote reqs duration(远程请求耗时):41.9 秒 — 跨节点 shuffle 获取time to deserialize(反序列化时间):2.2 秒
大部分 shuffle 数据(228.3 MiB)从远程 Executor 读取,少部分(15.3 MiB)来自本地任务。41.9 秒的远程请求时间包括网络延迟和调度开销 — 这对分布式集群上的跨节点 shuffle 来说是典型的。
Shuffle 写入器类型为 hash(在计划中可见),即按 group-by 键进行哈希分区以供最终聚合使用。
第五节:AQE 实战 — 512 → 149 个分区
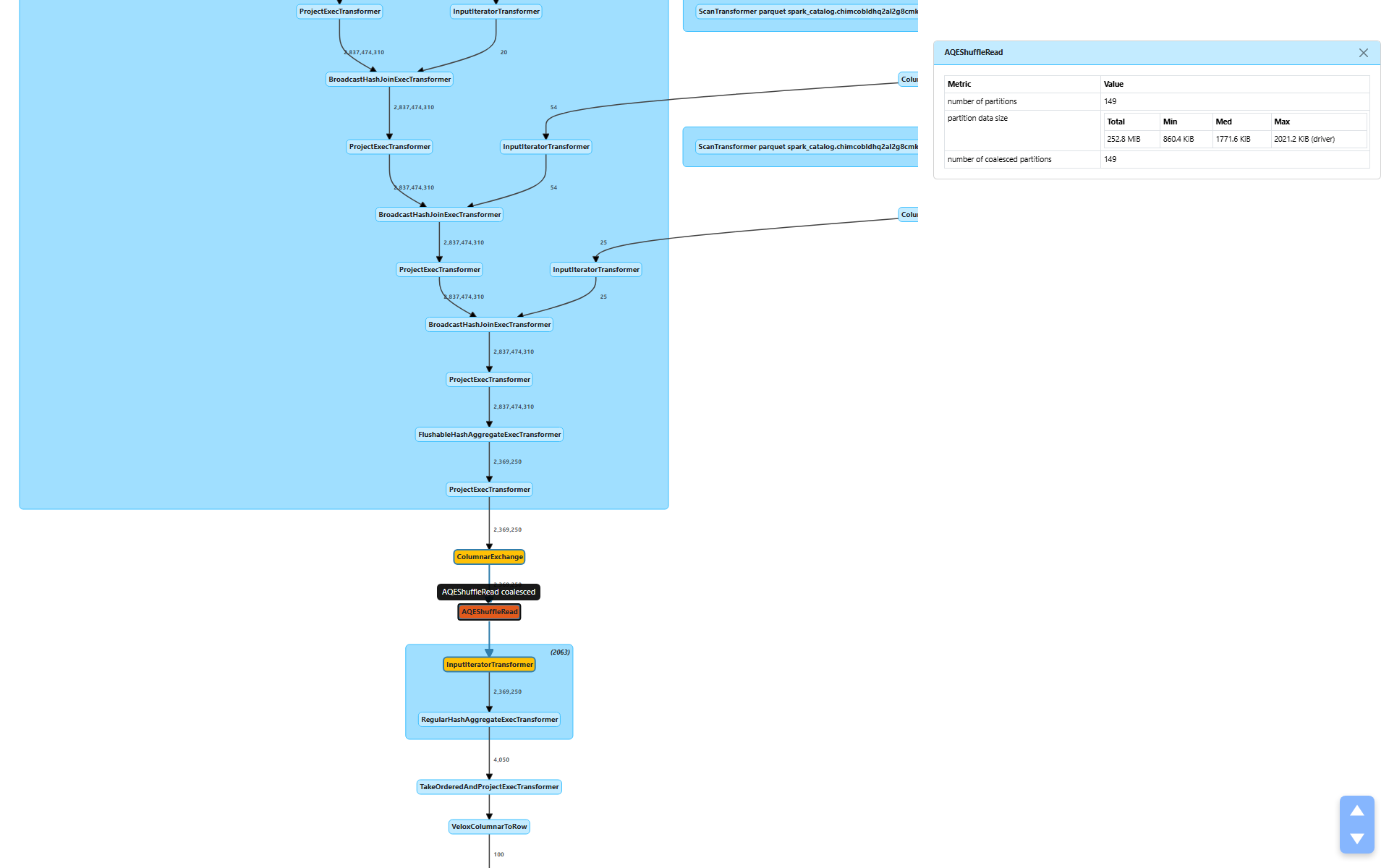
Shuffle 之后,AQEShuffleRead(节点 [6])介入:
number of coalesced partitions(合并的分区数):149 — AQE 将 512 个分区合并为 149 个partition data size(分区数据大小):252.8 MiB 总计,目标约 1.7 MiB/分区
AQE 检查了 shuffle 输出的统计信息,判定 512 个分区对于 252.8 MiB 的数据来说太多了。按 512 个分区计算,每个分区平均不到 500 KiB — 不值得 512 个任务的调度开销。通过合并到 149 个分区,每个任务处理更合理的约 1.7 MiB 数据。
没有检测到倾斜分区(numSkewedPartitions 指标缺失),因此 AQE 只应用了合并,没有进行倾斜处理。
这是第二部分中讨论的 AQE 如何利用指标进行运行时决策的完美示例。Stage 1 的 shuffle 写入统计直接影响了 Stage 2 的分区数。
第六节:最终聚合与结果 — 4,050 → 100 行
最终聚合
RegularHashAggregateExecTransformer(节点 [4])执行部分聚合结果的最终合并:
- 输入:2,369,250 行,分布在 149 个任务中
number of output rows(输出行数):4,050 — 最终分组数time of aggregation(聚合时间):3.2 秒peak memory bytes(峰值内存):194.4 MiB(每个任务 1.3 MiB)- 无 Spill
部分聚合已经完成了繁重的工作 — 最终聚合只需合并预聚合的分组。230 万个部分行在 3.2 秒内折叠为 4,050 个最终分组。轻而易举。
Top-100 排序与结果交付
TakeOrderedAndProjectExecTransformer 接收 4,050 行,排序后返回前 100 条。然后 VeloxColumnarToRow 将列式结果转换为行格式交付给驱动程序:
number of output rows(输出行数):100
从 33 亿行到 100 行。这就是整个查询。
全景回顾 — 指标告诉了我们什么
让我们退后一步,用关键指标审视完整的执行流程:
扫描 catalog_sales:33 亿原始行 → 28 亿行(4.5 分钟,2.1 GiB 来自 SSD 缓存)
↓ 应用了 9,380 个动态过滤器,跳过了 2,757 个行组
Join × 4(广播):28 亿行经过每个 join,零Spill
↓
部分聚合:28 亿 → 230 万行(1,200 倍缩减)
↓ WholeStageCodegenTransformer:26.2 分钟总原生管道时间
Shuffle:写入 243.6 MiB(哈希,512 个分区)
↓
AQE:512 → 149 个分区(合并)
↓
最终聚合:230 万 → 4,050 行(3.2 秒)
↓
Top-100 排序 → 返回 100 行
从指标中得到的关键结论
1. 缓存为王。 零字节来自远程存储,一切来自本地 SSD。910.9 GiB 的表只需要 2.1 GiB 的实际读取 — 通过列式存储效率和谓词下推实现了 99.8% 的缩减。
2. 行组裁剪成效显著。 跳过了 2,757 个行组。Velox 使用 Parquet/Delta 的 min-max 统计信息在读取任何数据之前就淘汰了整个行组。这是 I/O 缩减的主要驱动力。
3. 动态过滤器发挥了作用。 扫描期间应用了 9,380 个过滤器,由 join Build 端在运行时生成。这些过滤器在数据到达 join 算子之前就淘汰了不匹配的行,避免了对数十亿行的无谓处理。
4. 全程零 Spill。 Join、聚合和 shuffle 全部在内存中完成。整个查询没有一个字节 Spill 到磁盘。维度表足够小可以广播,部分聚合在 shuffle 之前缩减了数据量。
5. AQE 合并切实有效。 512 → 149 个分区用于最终聚合。没有 AQE 的话,我们将有 512 个任务,每个处理不到 500 KiB — 调度开销得不偿失。
6. 瓶颈在原生管道。 26.2 分钟的 WholeStageCodegenTransformer,涵盖了 33 亿行的扫描、28 亿行的四个 join 和部分聚合。这是真正的工作所在,全部在 Velox 的向量化原生引擎中执行。
7. wallNanos 沿树上升递增。 每个父算子的 Wall Clock Time 包含子算子的等待时间。最外层 join 显示 2.8 分钟,不是因为它本身慢,而是因为它包含了扫描、三个内层 join 及所有 I/O 的时间。这证实了第四部分中的注意事项 — 阅读 Wall Clock Time 指标时,请始终将算子树的结构纳入考量。
总结
这次实战演示表明,指标不只是屏幕上的数字 — 它们是一个叙事。每个指标都在回答一个具体的问题:
- 数据从哪里来? → I/O 层级指标(全部来自 SSD 缓存)
- 避免了多少工作? → 行组裁剪和动态过滤器
- 数据量在哪里骤降? → 聚合(1,200 倍缩减)
- 是否存在资源压力? → Spill 指标(全程为零)
- 优化器是否帮上了忙? → AQE 合并(512 → 149 个分区)
当你下次打开 Spark UI 查看一个慢查询时,你已经具备了解读每个指标、理解其含义、并精确定位瓶颈所在的能力。
在第一部分中,我们学习了五种指标类型并建立了完整的参考手册。在第二部分中,我们追踪了指标在 Spark 内部的流转机制以及 AQE 如何利用它们。在第三部分中,我们探索了扩展 API、UI 渲染和 REST 端点。在第四部分中,我们了解了 Gluten 如何扩展指标系统以支持原生执行。在第五部分中,我们深入了 Gluten 原生端的指标机制。在第六部分(本文)中,我们将所有知识融会贯通 — 通过走读一个真实的 TPC-DS 查询,展示每个指标如何讲述执行故事的一部分。本系列到此结束。