Spark Web UI 的 SQL 标签页一直有一个查询计划可视化功能。它将物理计划展示为 DAG——算子作为节点,数据流作为边。理论上,这是 Spark 中最强大的调试工具之一。但实际上,对于复杂查询来说,它几乎不可用。
现在,一切都变了。 SPARK-55785 重新设计了 SQL 执行计划可视化——紧凑布局、交互式指标面板,以及一目了然的边标签。
问题所在
旧的可视化将所有指标塞进每个节点标签中:
HashAggregate
number of output rows: total (min, med, max)
5,000,000 (1,250,000, 1,250,000, 1,250,000)
time in aggregation build: total (min, med, max)
2.3s (500ms, 575ms, 650ms)
peak memory: total (min, med, max)
512.0 MiB (128.0 MiB, 128.0 MiB, 128.0 MiB)
avg hash probe bucket list iters: ...
1.2 (1.1, 1.2, 1.3)
在一个真实查询中有 30 多个算子时,你得到的是一堵文字墙,没有任何重点突出。最关键的信息——哪个算子慢?数据在哪里膨胀?在哪里被过滤?——都淹没在视觉噪音中。
解决方案
紧凑模式:见林不见木
新的默认视图只显示算子名称。没有指标干扰。计划结构一目了然:
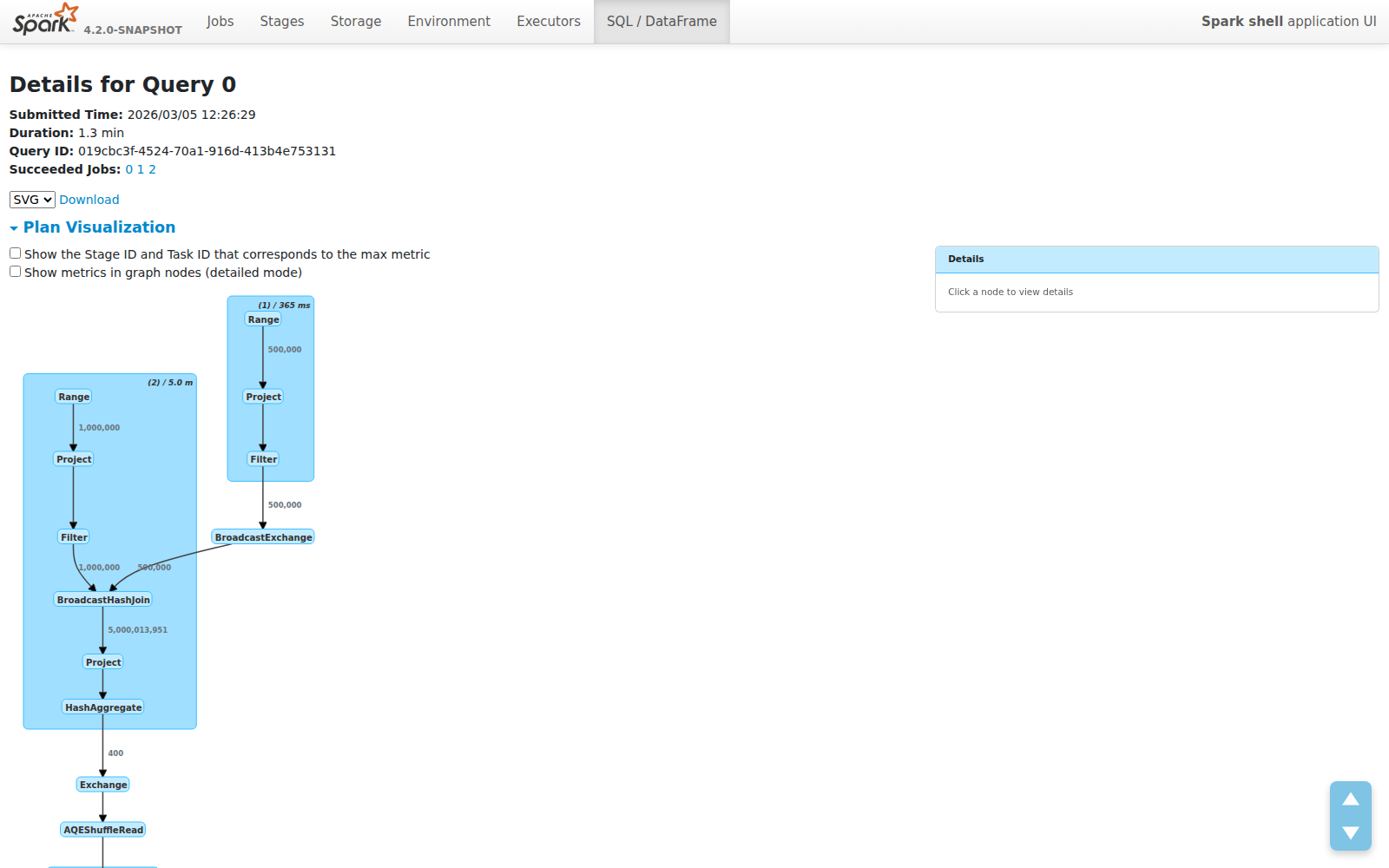
每个节点只是算子名称。每个集群显示 WholeStageCodegen 阶段编号和总耗时。计划可以在一个屏幕内展示,而不需要无尽滚动。
边标签:数据流一目了然
最有价值的改进不在节点上——而在边上。行数现在出现在每条边上,精确显示算子之间流动的数据量:
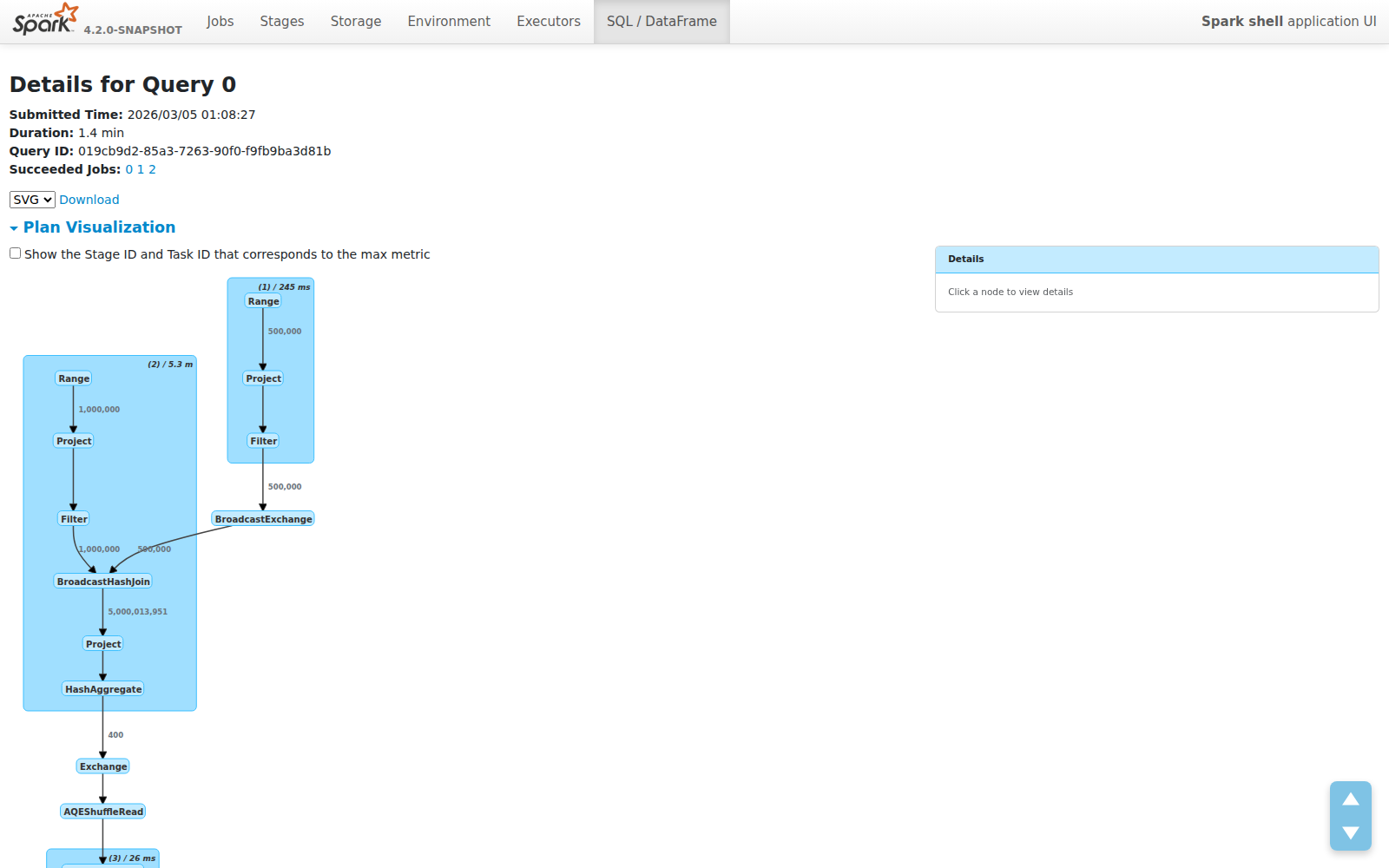
这使得几类性能问题立即可见:
- Join 膨胀 —— 1M × 500K 输入产生 5B 行?你会在边标签上立即看到。
- 过滤效果 —— 你的过滤器将 5B 行减少到 400 行?边标签直接告诉你,无需点击任何东西。
- 聚合影响 —— 直接看到你的 GROUP BY 将数据集压缩了多少。
这些是工程师在调试慢查询时最先问的问题。以前,你需要在脑中追踪指标表或使用 EXPLAIN 输出。现在答案就在图上。
点击查看详情:指标侧边面板
需要完整的信息?点击任意节点,一个侧边面板会滑入,展示结构化的指标表:
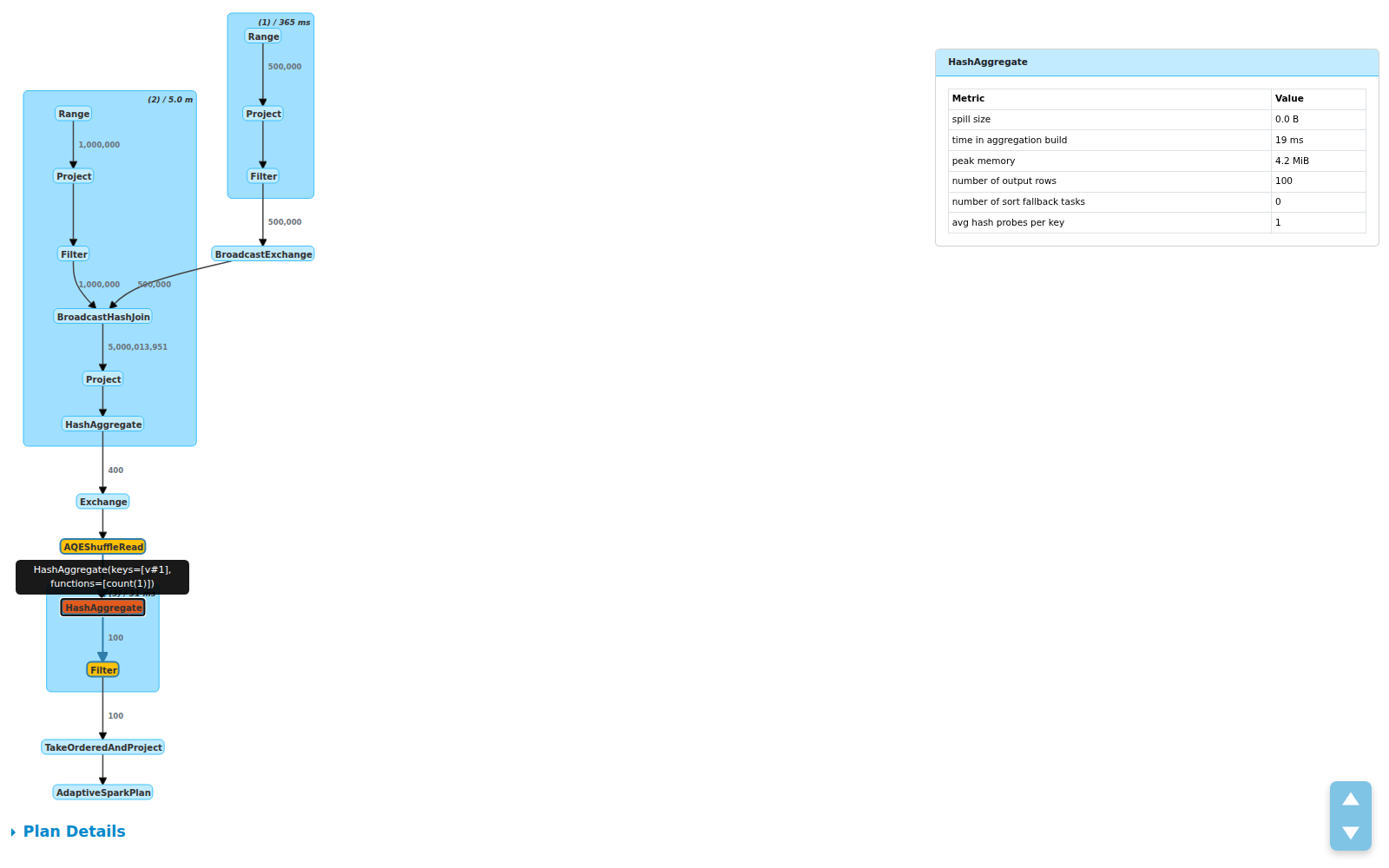
面板显示:
- 每个指标的 Total / Min / Med / Max 分解
- 鼠标悬停时的算子描述,用于区分相同名称的算子(当你有多个
HashAggregate节点时非常有用) - 点击集群可查看所有子算子指标的分组展示
这种设计参考了 Databricks 的查询分析器,并为开源 Spark UI 做了适配。
模式切换:你的选择
更喜欢旧的详细视图?一个复选框让你在紧凑模式和详细模式之间切换。在详细模式下,指标以 10px 字体渲染在图节点内:
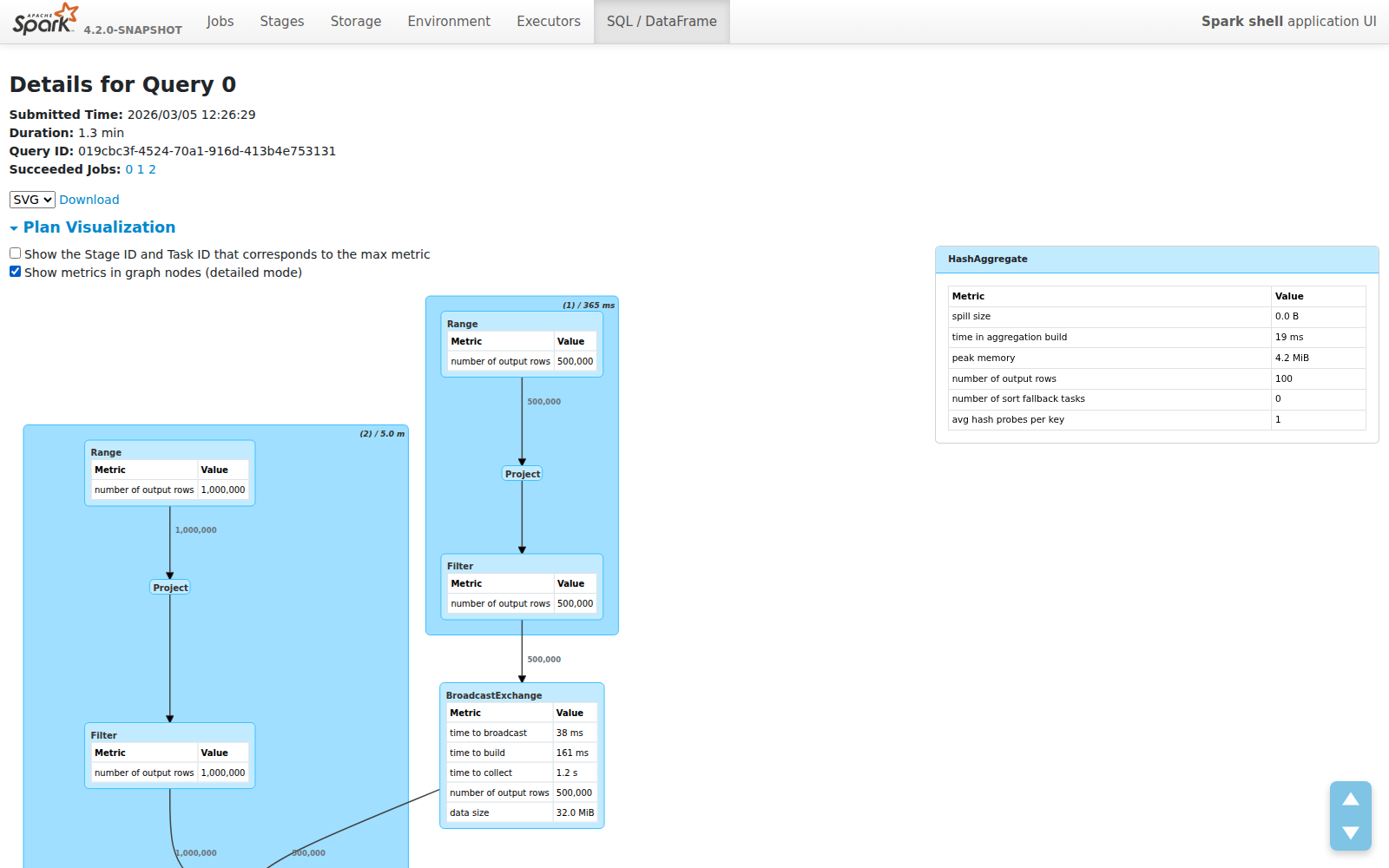
你的偏好保存在 localStorage 中——UI 会记住你的选择。
设计决策
值得说明的几个选择:
为什么选择边标签而非节点指标? 因为最重要的性能信号是算子之间的数据量,而不是单个算子的内部细节。边标签在计划层面回答"我的数据发生了什么?“节点指标回答"为什么这个特定算子慢?"——后者属于详情面板,而不是概览视图。
为什么使用纯文本标签而非 HTML? 旧的可视化使用 dagre-d3 的 labelType: "html" 在节点内进行富文本格式化。这导致渲染不一致、使暗黑模式支持更困难,并产生过大的节点。纯文本标签更轻量、更可预测,让 dagre-d3 正确地自动调整节点大小。
为什么用侧边面板而非工具提示? 指标表可能很大——6 个以上指标,每个都有 Total/Min/Med/Max 列。工具提示会被裁剪或重叠。固定的侧边面板提供稳定、可滚动的空间,并且不会遮挡图形。
未来计划
这是更广泛的 Spark Web UI 现代化 工作的一部分。正在讨论的未来改进包括:
- 为单个选定算子显示数据流路径
- 通过颜色高亮瓶颈算子(时间/行数热力图)
- 边标注数据大小(字节),而不仅仅是行数
本功能作为 SPARK-55785(PR #54565)贡献。感谢 @sarutak 和 @gengliangwang 的审阅,以及提出的边标签建议。